사전학습 된 모델(pretrained models)을 사용하는 것은 굉장히 유용하다. 이제 막 머신러닝(딥러닝)에 첫 발을 내딛는 나와 같은 초심자도 딥러닝 전문가들이 시간과 지식을 갈아 넣어 만들어 놓은 모델들을 통해 빠르고 쉽게, 그리고 높은 성능을 내는 모델을 사용할 수 있기 때문이다. 심지어 딥러닝에 대한 지식이 없는 사람도, 사전학습 된 모델을 통해 꽤 그럴듯한 모델을 만들 수 있다. 이처럼 사전학습 된 모델을 내가 수행하려는 작업에 맞추어 파라미터를 조정하는 것을 파인 튜닝(Fine-Tuning)이라고 한다.
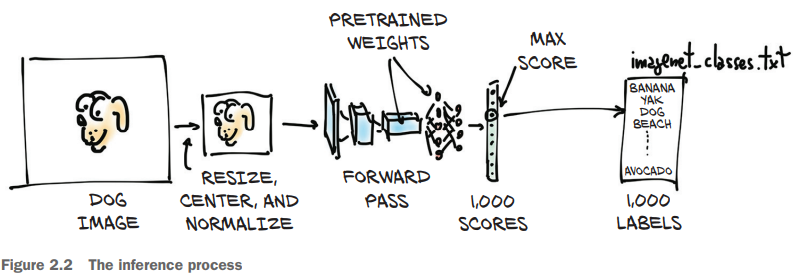
이제 어떻게 파이토치로 사전학습 된 모델을 사용할 수 있는지 살펴보자. 파이토치를 사용하기 위한 가상환경이나 필요한 라이브러리는 미리 다운받아놓았다. CV(Computer Vision)과 관련된 딥러닝 모델은 torchvision.models에 들어있다.

dir() 함수를 통해 torchvision.models에 포함된 클래스와 속성, 메서드들을 출력할 수 있다. 'AlexNet', 'DensenNet', 'EfficientNet' 등이 보인다. 대문자로 된 것들은 구조(architecture)가 서로 다른 모델 클래스들이다. 이처럼 파이토치는 자주 사용되고 인기 있는 딥러닝 모델들을 미리 구현하여 제공하고 있다. 위 그림에는 잘렸지만 밑으로 내리면 소문자로 되어있는 되어있는 것들도 있는데, 위와 같은 모델 클래스들을 인스턴스화 하여 제공하는 편리한 함수들이다. 예를 들어 resnet101은 101개의 layers가 존재하는 ResNet 인스턴스를 return하고, resnet18은 18개의 layers가 존재하는 ResNet 인스턴스를 반환한다.
그 중에서 AlexNet을 잠시 살펴보자. AlexNet은 2012년에 진행된 ILSVRC( ImageNet Large Scale Visual Recognition Challenge)에서 15.4%의 top 5 에러율을 보이며 우승을 차지한 모델이다. 그에 반해 심층 신경망을 사용하지 않은 모델이 26.2%의 에러율로 2위를 차지했는데, 이것이 CV 분야에 딥러닝의 잠재력을 일깨워준 사건이라고 한다. 예측 성능은 꾸준히 증가해서, 최근의 딥러닝 아키텍처(모델)들은 약 3%의 top-5 에러율을 보인다고 한다.

입력 이미지가 그림의 왼쪽으로 들어가서 5개의 stack(filters)을 통과하고, 마지막에 4,096개의 1차원 벡터로 표현된다. 그리고 1,000개의 labels에 대한 확률값이 계산된 1차원 벡터로 표현되는 것이 AlexNet의 기본 구조이다. 자세히는 모르겠지만, AlexNet을 input을 넣으면 그것에 대한 output을 출력하는 하나의 함수로 생각해보자.
model = models.AlexNet()
input_path = "../data/p1ch2/bobby.jpg"
img = Image.open(input_path).convert('RGB')
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
img_tensor = preprocess(img)
img_tensor = img_tensor.unsqueeze(0)
위와 같은 코드를 실행하여 model 객체의 입력으로 넣는다면 어떻게 될까? 정답을 출력할 것이란 우리의 예상과는 다르게 쓰레기 값(garbage value)가 출력되게 된다. 그 이유는 "AlexNet"은 어떠한 데이터로도 훈련(training)되어 있지 않은, 정말 말 그대로 구조만 갖춰진 모델이기 때문이다. 따라서, 파라미터 값들이 null이거나 랜덤한 상태로 초기화되어 있을 것이다. 우리가 원하는 Train data를 통하여 학습된, 제대로된 "pretrained model"을 사용하기 위해서는 다른 방법이 필요하다. 위에서 말한 소문자로 되어있는 "alexnet"과 같은 함수들이 그것이다. 이러한 함수들을 사용하면 학습된 파라미터를 가진 모델들을 인스턴스화 하여 반환해주기 때문에 사전학습된 모델을 사용할 수 있다.
"resnet101"을 사용하여 101개의 Layers를 가진 ResNet모델을 인스턴스화 할 수 있다. 아래의 코드를 Jupyter notebook에서 실행시켜보자.
model = models.resnet101(weights=True)
위 코드를 실행시키면 사전 학습된 파라미터들을 다운로드 받는 상태창이 나오고, 다운로드가 완료되면 model 객체로 사전학습된 resnet101을 사용할 수 있게 된다. resnet101의 파라미터의 개수가 4,450만개 정도 되기 때문에 다운로드가 끝나는데 몇 분 정도 소요된다.

위 그림처럼 model을 출력하면 ResNet 구조의 정보를 볼 수 있다. 저 레이어들이 어떤 의미를 하는지 지금은 몰라도 된다. 단지 벽돌 하나가 건축물의 일부가 되듯, 레이어 하나가 뉴럴 네트워크를 구성하는 하나의 요소라고 보면 될 것 같다.
그리고 아래와 같이 이미지를 변환시키는 함수 preprocess를 정의해주자.
from torchvision import transforms
from PIL import Image
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)])
입력으로 넣은 그림은 위와 같다. 그리고 model 객체의 입력으로 넣기 위해 preprocess()를 이용하여 이미지를 변환해해준다.
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)

보통 validation이나 test를 할 때, model.eval()을 선언하여 사용해야한다. 그래야 dropout이나 batch regularization이 비활성화 되어 제대로 테스트 결과가 나온다고 하는데, 자세한건 나중에 나온다고 하니 우선 그런가보다 하고 넘어가자.

변환된 img를 model의 out으로 넣어준다.
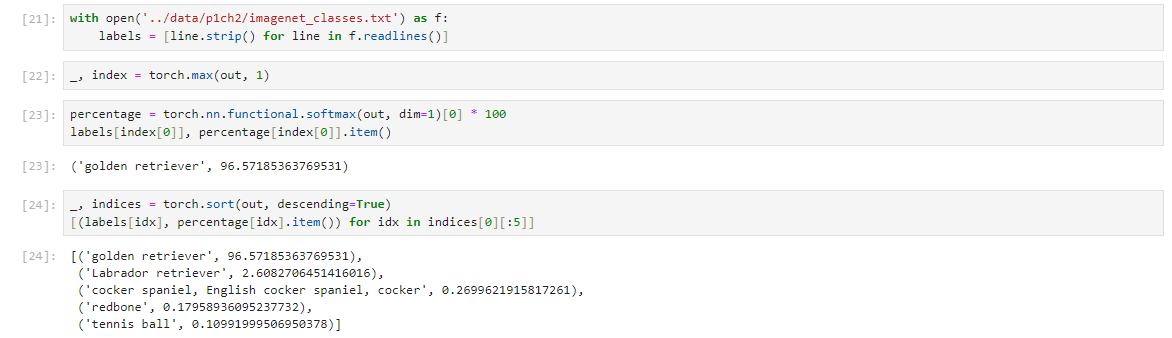
imagenet_classes.txt파일은 1,000개의 ImageNet 데이터셋 클래스가 라벨링 되어있는 파일이다. 우리의 input data를 model(resnet101)에 넣었을 때 어떤 class일 확률이 가장 높게 나오는지 확인하기 위한 작업이다. 결과적으로 '골든 리트리버'가 96.6%로 나오고, 그 다음으로 '래브라도 리트리버' 등이 다음 순서로 나오는 것을 볼 수 있었다.
References
1. Deep Learning with Pytorch, Eli Stevens, Luca Antiga, Thomas viehmann
'인공지능 > PyTorch' 카테고리의 다른 글
| Tensor of PyTorch (0) | 2024.02.28 |
|---|
